So, the global industrial supply chain is apparently in a tailspin. Volatility, geopolitical bickering, and profit margins thinner than a politician’s promise. We’ve spent decades engineering these complex webs for pure, unadulterated cost efficiency. Now? Tariffs, material gatekeeping, regulatory whiplash, and Mother Nature throwing tantrums. And our esteemed industrial leaders are suddenly realizing that just looking at old spreadsheets from the good ol’ days isn’t going to cut it. They’re talking about evolving beyond those tired, backward-looking financial metrics. Not ditching them, mind you, just… adding something. Something called transparent, ‘should-cost’ engineering. Sounds fancy, doesn’t it? Apparently, this is how we’re going to achieve resilience and get suppliers to play nice. More jargon to sift through, more consulting dollars likely to be spent.
This whole notion of ‘cost engineering’ — or whatever flavor of the week they’re calling it: techno-economic analysis, zero-based costing, product cost management — it’s presented as this grand, forward-looking methodology. But let’s be honest, for twenty years I’ve seen Silicon Valley and corporate America repackage old ideas with shiny new labels. The pitch is always the same: efficiency, transparency, data-driven insights. And sure, sometimes it sticks. But more often, it’s a lot of smoke and mirrors before the next wave of consultants rolls in.
Transparency as a Competitive Advantage
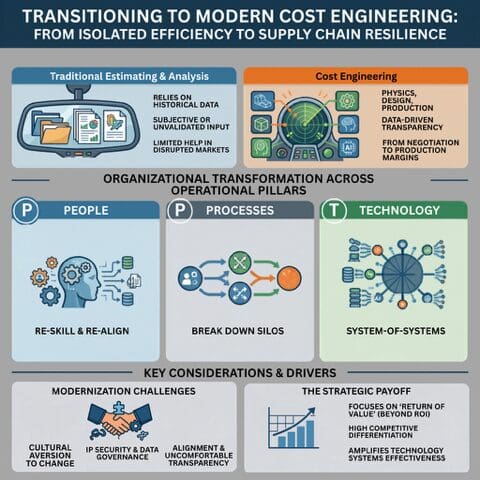
Here’s the rub with the old way. Traditional cost estimating was essentially a historical reenactment. You’d dig through dusty financial records, pore over design docs, and make educated guesses. It was subjective, often a black box. When the supply chain was as stable as bedrock, this stuff was, fine. Useful, even. But now? With everything from trade wars to freak blizzards disrupting the flow, those backward glances are about as helpful as a pager in a bitcoin mine.
This digital age, it’s laid bare the embarrassing lag time and the built-in competitive disadvantages of those old-school methods. They’re simply not enough for managing costs in this chaotic modern landscape. It’s like showing up to a drone race with a horse and buggy.
But this newfangled ‘modern cost engineering’? Oh, it’s forward-looking. No guessing here. They’re talking about using 3D CAD, digital twins, AI simulations. Stuff that’s supposed to tell you what a product should cost based on pure physics and design. Granular, validated input, they claim. A baseline for data-driven transparency. Sounds great on paper. But the article itself admits it’s not easy and has ‘massive downstream impact’ on people, processes, and technology. And it shifts the burden from haggling over prices to suppliers proving their production prowess. Who’s really making money when you factor in the tech upgrades and the inevitable retraining headaches?
Impact on People, Processes, and Technology
So, the big promise is that moving to this ‘should-cost’ model will rewire everything. Organizations have to tackle transformations across three core pillars, or so the theory goes.
First, People. Everyone in the supply chain apparently needs a skill upgrade. Forget just managing costs; it’s about maintaining profitability across the entire loop, from the initial whisper of demand to the final customer service call. Since AI is supposedly handling the grunt work of data management (color me skeptical), human estimators need to pivot. They’ll need to interpret complex product models, material science, and all sorts of operational mumbo jumbo. The cost engineer isn’t just crunching numbers anymore; they’re supposed to be translating manufacturing physics into strategic business recommendations, guiding procurement teams on vendor selection and performance benchmarks. Basically, they’re turning into high-paid consultants on retainer.
Then there are the Processes. This ‘cost engineering’ business demands the demolition of siloed departments. Pressure’s on to integrate cost expertise into cross-functional teams, slashing those pesky gaps in design, manufacturing, and procurement. Procurement itself undergoes a metamorphosis: no more simple price negotiations. Instead, teams are supposed to use ‘should-cost’ data to collaboratively improve supplier manufacturing processes. The goal? Mutual profitability and supply chain resilience. Sounds idyllic, doesn’t it? It also sounds like a lot of extra meetings and potential for new kinds of finger-pointing when the ‘collaborative improvement’ goes south.
And finally, Technology. To make all this wizardry happen, companies need to pony up for new digital tools. At the heart of it all is this concept of an ‘industrial data fabric’ (IDF). Apparently, as businesses adopt cost engineering principles, they’ll naturally gravitate towards an IDF that fits their vibe. It’s not a single piece of tech, but a ‘capability set’ built on ‘system-of-systems thinking’. It requires bidirectional data communication and transparency. All well and good, but who’s building and maintaining this data fabric? And at what cost? My money’s on the tech vendors getting a nice, fat payday.
“Rather than just negotiating price, teams use should-cost data to collaboratively improve a supplier’s manufacturing processes, ensuring mutual profitability and supply chain resilience.”
This quote, right here, is the crux of it. On the surface, it sounds like enlightened cooperation. But peel back the PR fluff, and it smells like a new way for big manufacturers to dictate terms and squeeze more performance out of suppliers under the guise of partnership. They get data on how suppliers should be operating, and if the supplier doesn’t meet those idealized targets, well, that’s their problem. It’s a shift in power, sure, but who truly holds the reins?
My unique insight here? This whole ‘should-cost’ engineering push is less about altruistic transparency and more about sophisticated cost control and supplier use in an era where traditional use points are eroding. It’s a digital arms race for operational intel, dressed up in the language of collaboration. We’ve seen this play out before: introduce a complex, data-intensive methodology, require significant tech investment, retrain personnel, and, at the end of the day, the entity with the most sophisticated data infrastructure and analytical capabilities wins. Right now, that’s usually the industrial giants. The question isn’t whether ‘should-cost’ engineering works, but who it works for and at whose expense.
Who’s Actually Paying for This ‘Should-Cost’ Revolution?
The fanfare around cost engineering often glosses over the substantial upfront investment. We’re talking about acquiring new software, potentially overhauling existing IT infrastructure, and, critically, investing in training and upskilling the workforce. Who shoulders these costs? Typically, it’s the large industrial players. And while they’re investing in new capabilities, they’re also positioning themselves to extract more value from their supplier networks. The suppliers, meanwhile, are often left to adapt or risk being left behind, facing pressure to adopt new systems and provide granular data that, while presented as collaborative, ultimately serves the buyer’s strategic interests. It’s a classic case of the rising tide lifting some boats much higher than others.
Why Does This Matter for Procurement Professionals?
Procurement pros are often the frontline in this shift. Their traditional role as price negotiators is evolving. They’re being asked to become data analysts, process improvement facilitators, and strategic partners. This requires a new skill set. Instead of just asking ‘What’s the price?’, they’ll need to ask ‘What should the price be, based on these physics and manufacturing constraints?’ and then work with suppliers to achieve that. It’s a more complex, data-driven, and potentially more impactful role, but it demands a significant learning curve and a willingness to move beyond traditional comfort zones. The risk is that without proper training and support, this ‘evolution’ just becomes another layer of managerial micromanagement.
**
🧬 Related Insights
- Read more: Two Boxes’ $3.2M AI Returns Bet: Saviors or Just Another Hype Machine?
- Read more: Bunker Fuel Costs Climb: Ocean Carriers Say Service Unaffected [Analysis]
Frequently Asked Questions**
What is the main goal of ‘should-cost’ engineering?
The primary goal is to move beyond historical cost data to understand the fundamental cost drivers of a product or process based on physics, design, and operational realities, enabling greater transparency and strategic decision-making.
Will ‘should-cost’ engineering replace traditional cost analysis?
Not entirely. It’s framed as an evolution, augmenting traditional backward-looking methods with forward-looking, data-driven analysis to build resilience and competitive advantage.
Are suppliers forced to adopt ‘should-cost’ methods?
While not explicitly stated as mandatory, suppliers will likely face increasing pressure to comply with their buyers’ adoption of ‘should-cost’ methodologies to remain competitive and secure contracts.


